มาดูกันดีกว่าครับว่า Alpha Go ทำงานยังไงข้อมูลที่ใช้ในการเขียนแกะมาจาก Mastering the game of Go with deep neural networks and tree search ซึ่งเป็นเปเปอร์ของทีม Deep Mind ครับ ผมคงไม่ได้ลงลึกในรายละเอียดมากนัก(เพราะยากมาก ผมก็เข้าใจไม่หมด) แต่จะอธิบายภาพใหญ่ๆของการทำงานของมัน
ก็ตามชื่อบทความ นั่นคือตัว Alpha Go นั้นผสมผสานเทคนิคสองอย่างเข้าด้วยกันคือ Tree Search และ Neural Networks(NN) หรือเครือข่ายประสาทเทียม ผมคงไม่ลงรายละเอียดว่า NN ทำงานยังไง เอาสรุปง่ายๆว่า มันเป็นกล่องที่จะให้คำตอบ โดยคำตอบที่ได้ มาจากการเรียนรู้ละกันครับ
กูเกิลแบ่งขั้นตอนการสร้าง NN เป็น 3 ขั้น นั่นคือ
1. สอน : NN ได้รับการป้อนบันทึกหมากจำนวน 30 ล้านตาเดิน แล้วให้พยายาม “เดา” หมากเม็ดถัดไปที่จะเดินลงมา NN ในขั้นนี้มี 2 ตัว คือ SL Policy และ Rollout Policy ซึ่งเหมือนกันทุกอย่างต่างกันตรงเวลาคิด(SL Policy ใช้เวลาหาคำตอบ 3 millisecond ส่วน Rollout ใช้ 2 microsecond แต่ความแม่นก็ต่างกันครึ่งต่อครึ่ง)
2. ซ้อม : เอา SL Policy จากขั้นตอนแรก มาแข่งกับตัวมันเอง(ในเวอร์ชั่นก่อนๆ)จนได้ข้อมูลมาอีก 30 ล้านตาเดินแล้วให้คะแนนถ้าตาเดินนั้นทำให้ชนะ ผลที่ได้จากขั้นตอนนี้เรียกว่า RL Policy กูเกิลบอกว่า RL Policy ชนะ SL Policy ได้มากกว่า 80% และลำพัง RL Policy ก็เพียงพอจะชนะโปรแกรมโกะอื่นๆในโลกมากกว่า 85%
3. สังเคราะห์ : เพื่อให้การตัดสินใจกว้างขึ้น กูเกิลตัดสินใจสร้าง NN ขึ้นอีกหนึ่งตัวที่ให้คำตอบเป็นความน่าจะเป็นที่จะชนะของการลงหมากในแต่ละตำแหน่ง(Probability to win) NN ตัวนี้ได้จากตำแหน่งหมากเวลาใดๆ เทียบกับผลลัพธ์สุดท้ายว่าเกมนั้นชนะหรือแพ้ ข้อมูลที่ใช้ได้จากการใช้ RL Policy แข่งกับตัวมันเอง อีก 30 ล้านตาเดิน เรียกว่า Value Policy
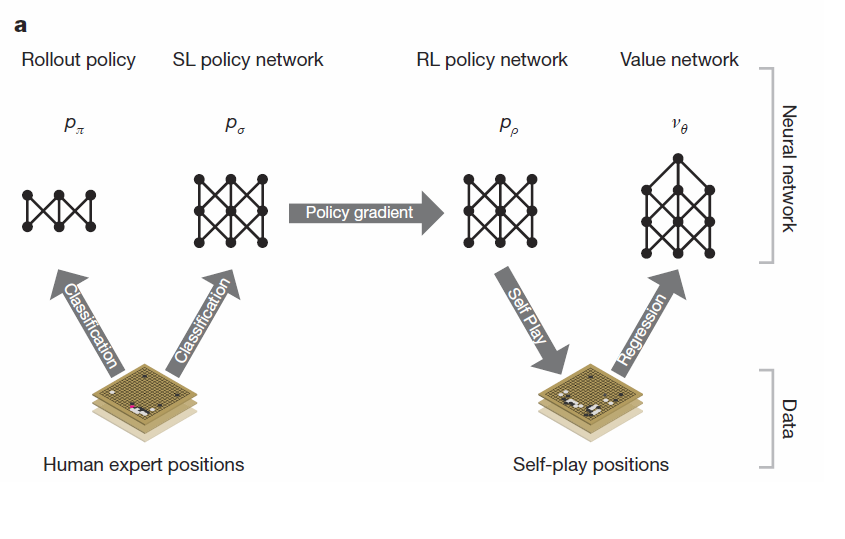
ภาพที่ 1 แสดงที่มาของ policy ทั้ง 4 ตัว
ถึงตรงนี้ รากฐานการประเมินของ Alpha Go พร้อมแล้ว ขั้นตอนถัดไปคือการเอามาใช้ ขอพักคอมพิวเตอร์ไว้แป๊ปนึง กลับมาลองนึกถึงเราเองว่าเวลาเราเล่นหมากรุก หรือโกะ นี่เราเล่นยังไง ผมว่าโดยรวมหลายๆคนจะเริ่มแบบนี้ครับ
1. กวาดตากว้างๆดูกระดาน ตัดตาเดินที่ไม่เมกเซนต์ออกไปให้หมดก่อน
2. ทดลองเดินดู(ในใจ) แล้วเดาว่าฝ่ายตรงข้ามจะเดินตอบโต้ยังไง
3. ย้ายไปลองเดินตาอื่น แล้วประเมินการตอบโต้
4. เลือกตาเดินที่ดีที่สุด
สิ่งที่กูเกิลทำก็ตามนั้นละครับ

เทคนิคที่ใช้ในการนี้เรียกว่า Monte carlo Tree Search
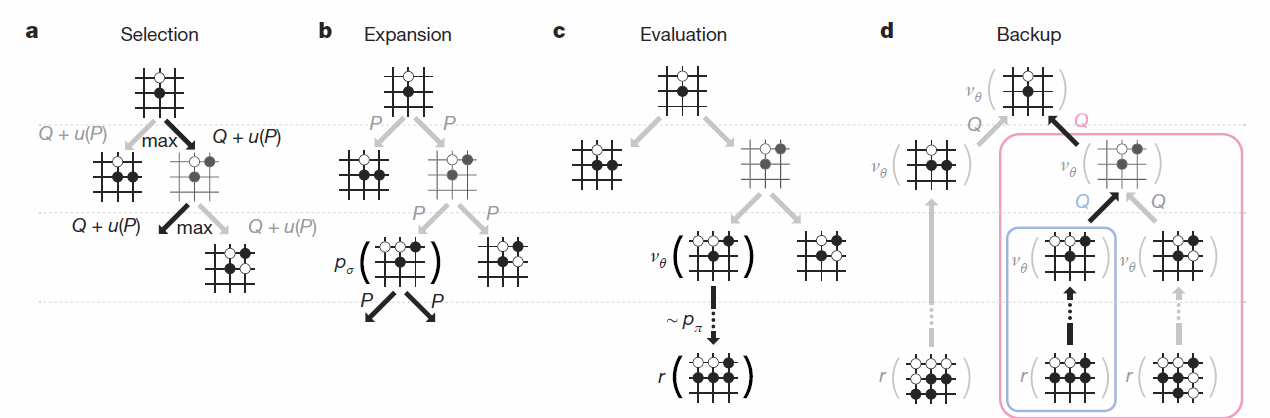
ภาพที่ 2 Monti Carlo Tree Search
1. จากภาพโปรแกรมจะเริ่มจากการกวาดตากว้างๆ หนึ่งรอบ ประเมินตาเดินทั้งหมดที่เป็นไปได้ ขั้นตอนนี้ใช้ SL Policy (ถ้าเป็นโปรจะเดินยังไง)ให้คะแนนแต่ละทางเลือก
2. เอาทางเลือกที่คะแนนดีๆ มาลองคิดต่อ โดยลองเดินตาถัดไปหลายๆแบบ โดยใช้ทั้ง SL Policy(โปรเดิน) RL Policy(เดินเอง)
3. ให้คะแนนแต่ละทางเลือกโดยใช้ Value Policy(เดินแบบนี้มีโอกาสชนะเท่าไหร่)ควบกับ Rollout Policy (ลองเดินต่อให้จบแบบหยาบๆ)
4. ทดลองเดินต่อจากข้อสอง(คือเดาหมากถัดไปอีกชั้น)
กระบวนการนี้จะวนไปเรื่อยๆ จนกว่าจะได้ผลลัพธ์ที่น่าพอใจ แล้วก็จะเลือกทางเดินที่ดีที่สุดไปใช้
มาดูตัวอย่างกันครับ
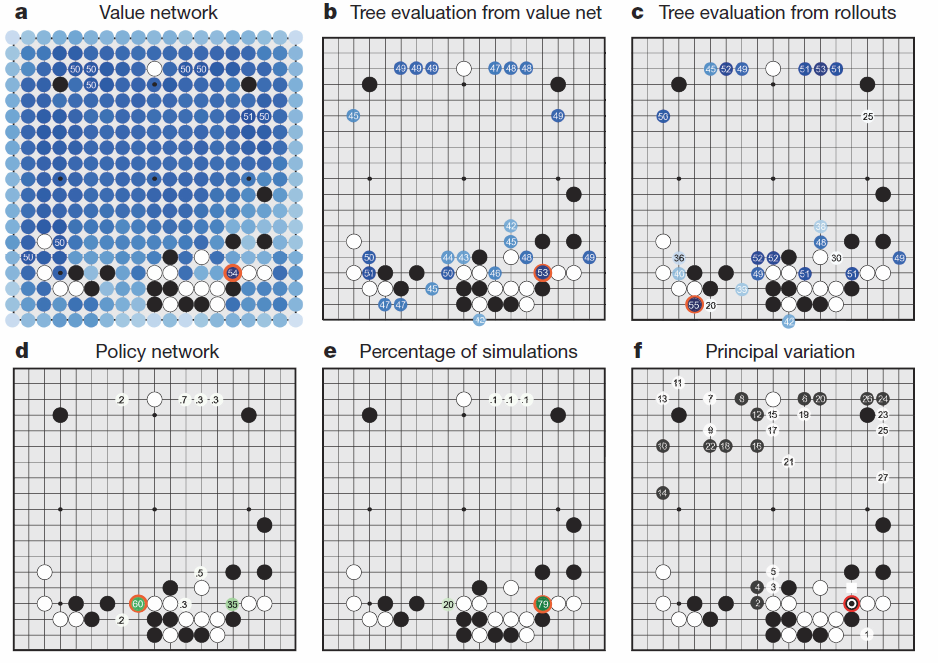
ภาพที่ 3 ตัวอย่างการเดินของ Alpha Go ในเกมกับ ฟานฮุ่ย
a. โปรแกรมทำการประเมินโอกาสชนะของตาเดินทั้งหมดโดยใช้ value policy ที่เป็นไปได้ สีเข้มคือน่าเดิน สีอ่อนคือไม่น่าเดิน ที่มีสีแดงวงไว้ คือตาเดินที่มีโอกาสสูงสุด
b.-d. คะแนนคำนวณแต่ละตำแหน่งจาก policy ต่างๆกัน
e. หมากที่โดนวงไว้คือ ตาเดินที่มีความน่าจะเป็นสูงสุดที่จะชนะ
f. คือรูปแบบการเดินที่พยากรณ์ไว้ทั้งหมดก่อนเดินตานี้ ซึ่ง ฟานฮุ่ย ลงหมากที่ตำแหน่ง 1 ตามที่ Alpha Go พยากรณ์ไว้
จบแล้วครับ สำหรับโครงสร้างคร่าวๆของ Alpha Go ใครจะต่อขยายภาคพิศดารก็เชิญตามสะดวก
fb note :
https://www.facebook.com/notes/panote-saechiew/how-alpha-go-work/1340692295948067

How Alpha Go Work
ก็ตามชื่อบทความ นั่นคือตัว Alpha Go นั้นผสมผสานเทคนิคสองอย่างเข้าด้วยกันคือ Tree Search และ Neural Networks(NN) หรือเครือข่ายประสาทเทียม ผมคงไม่ลงรายละเอียดว่า NN ทำงานยังไง เอาสรุปง่ายๆว่า มันเป็นกล่องที่จะให้คำตอบ โดยคำตอบที่ได้ มาจากการเรียนรู้ละกันครับ
กูเกิลแบ่งขั้นตอนการสร้าง NN เป็น 3 ขั้น นั่นคือ
1. สอน : NN ได้รับการป้อนบันทึกหมากจำนวน 30 ล้านตาเดิน แล้วให้พยายาม “เดา” หมากเม็ดถัดไปที่จะเดินลงมา NN ในขั้นนี้มี 2 ตัว คือ SL Policy และ Rollout Policy ซึ่งเหมือนกันทุกอย่างต่างกันตรงเวลาคิด(SL Policy ใช้เวลาหาคำตอบ 3 millisecond ส่วน Rollout ใช้ 2 microsecond แต่ความแม่นก็ต่างกันครึ่งต่อครึ่ง)
2. ซ้อม : เอา SL Policy จากขั้นตอนแรก มาแข่งกับตัวมันเอง(ในเวอร์ชั่นก่อนๆ)จนได้ข้อมูลมาอีก 30 ล้านตาเดินแล้วให้คะแนนถ้าตาเดินนั้นทำให้ชนะ ผลที่ได้จากขั้นตอนนี้เรียกว่า RL Policy กูเกิลบอกว่า RL Policy ชนะ SL Policy ได้มากกว่า 80% และลำพัง RL Policy ก็เพียงพอจะชนะโปรแกรมโกะอื่นๆในโลกมากกว่า 85%
3. สังเคราะห์ : เพื่อให้การตัดสินใจกว้างขึ้น กูเกิลตัดสินใจสร้าง NN ขึ้นอีกหนึ่งตัวที่ให้คำตอบเป็นความน่าจะเป็นที่จะชนะของการลงหมากในแต่ละตำแหน่ง(Probability to win) NN ตัวนี้ได้จากตำแหน่งหมากเวลาใดๆ เทียบกับผลลัพธ์สุดท้ายว่าเกมนั้นชนะหรือแพ้ ข้อมูลที่ใช้ได้จากการใช้ RL Policy แข่งกับตัวมันเอง อีก 30 ล้านตาเดิน เรียกว่า Value Policy
ภาพที่ 1 แสดงที่มาของ policy ทั้ง 4 ตัว
ถึงตรงนี้ รากฐานการประเมินของ Alpha Go พร้อมแล้ว ขั้นตอนถัดไปคือการเอามาใช้ ขอพักคอมพิวเตอร์ไว้แป๊ปนึง กลับมาลองนึกถึงเราเองว่าเวลาเราเล่นหมากรุก หรือโกะ นี่เราเล่นยังไง ผมว่าโดยรวมหลายๆคนจะเริ่มแบบนี้ครับ
1. กวาดตากว้างๆดูกระดาน ตัดตาเดินที่ไม่เมกเซนต์ออกไปให้หมดก่อน
2. ทดลองเดินดู(ในใจ) แล้วเดาว่าฝ่ายตรงข้ามจะเดินตอบโต้ยังไง
3. ย้ายไปลองเดินตาอื่น แล้วประเมินการตอบโต้
4. เลือกตาเดินที่ดีที่สุด
สิ่งที่กูเกิลทำก็ตามนั้นละครับ
ภาพที่ 2 Monti Carlo Tree Search
1. จากภาพโปรแกรมจะเริ่มจากการกวาดตากว้างๆ หนึ่งรอบ ประเมินตาเดินทั้งหมดที่เป็นไปได้ ขั้นตอนนี้ใช้ SL Policy (ถ้าเป็นโปรจะเดินยังไง)ให้คะแนนแต่ละทางเลือก
2. เอาทางเลือกที่คะแนนดีๆ มาลองคิดต่อ โดยลองเดินตาถัดไปหลายๆแบบ โดยใช้ทั้ง SL Policy(โปรเดิน) RL Policy(เดินเอง)
3. ให้คะแนนแต่ละทางเลือกโดยใช้ Value Policy(เดินแบบนี้มีโอกาสชนะเท่าไหร่)ควบกับ Rollout Policy (ลองเดินต่อให้จบแบบหยาบๆ)
4. ทดลองเดินต่อจากข้อสอง(คือเดาหมากถัดไปอีกชั้น)
กระบวนการนี้จะวนไปเรื่อยๆ จนกว่าจะได้ผลลัพธ์ที่น่าพอใจ แล้วก็จะเลือกทางเดินที่ดีที่สุดไปใช้
มาดูตัวอย่างกันครับ
ภาพที่ 3 ตัวอย่างการเดินของ Alpha Go ในเกมกับ ฟานฮุ่ย
a. โปรแกรมทำการประเมินโอกาสชนะของตาเดินทั้งหมดโดยใช้ value policy ที่เป็นไปได้ สีเข้มคือน่าเดิน สีอ่อนคือไม่น่าเดิน ที่มีสีแดงวงไว้ คือตาเดินที่มีโอกาสสูงสุด
b.-d. คะแนนคำนวณแต่ละตำแหน่งจาก policy ต่างๆกัน
e. หมากที่โดนวงไว้คือ ตาเดินที่มีความน่าจะเป็นสูงสุดที่จะชนะ
f. คือรูปแบบการเดินที่พยากรณ์ไว้ทั้งหมดก่อนเดินตานี้ ซึ่ง ฟานฮุ่ย ลงหมากที่ตำแหน่ง 1 ตามที่ Alpha Go พยากรณ์ไว้
จบแล้วครับ สำหรับโครงสร้างคร่าวๆของ Alpha Go ใครจะต่อขยายภาคพิศดารก็เชิญตามสะดวก
fb note : https://www.facebook.com/notes/panote-saechiew/how-alpha-go-work/1340692295948067