ช่วงนี้เห็นหลายบริษัททุ่มงบกับ AI หนักมาก ทั้งซื้อโมเดลใหม่ จ้างทีม Prompt Engineering ทำ RAG ทำ Agent กันเต็มไปหมด แต่สุดท้ายหลายโปรเจกต์กลับไปไม่ถึงจุดที่ใช้งานจริงได้สักที
พอได้อ่านบทความนี้แล้วรู้สึกว่า “เออ มันตรงมาก”
ข่าวต้นฉบับ:
https://aimagazine.com/news/tealium-why-enterprise-ai-is-orchestration-problem
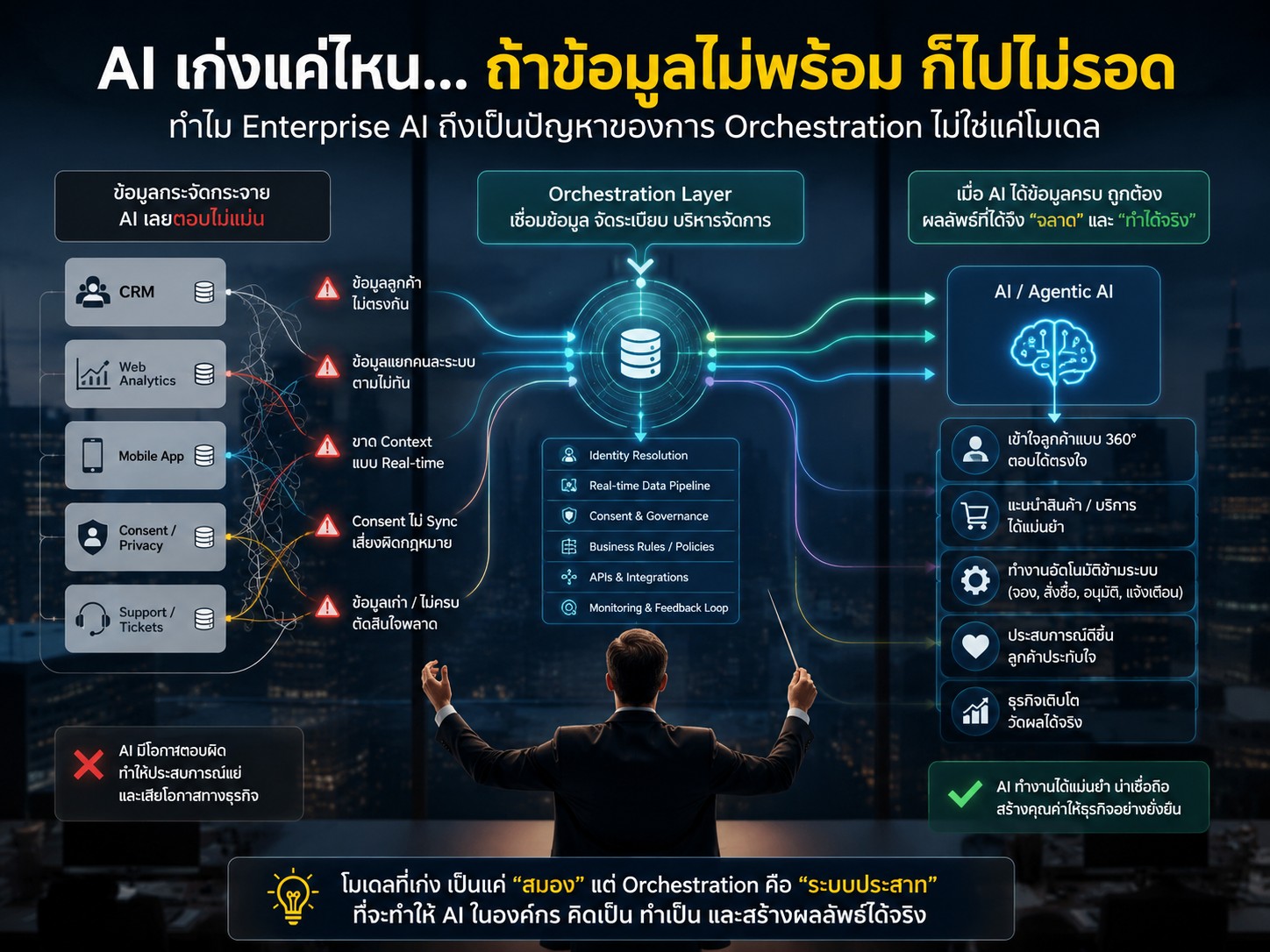
บทความพูดถึงประเด็นที่คนชอบมองข้าม คือปัญหาของ AI ในองค์กรจำนวนมาก จริงๆ ไม่ได้อยู่ที่ตัวโมเดล แต่เป็น “ระบบหลังบ้าน” ที่ส่งข้อมูลให้ AI มากกว่า
หลายองค์กรคิดว่าเปลี่ยนไปใช้โมเดลใหม่ แพงขึ้น ฉลาดขึ้น เดี๋ยวทุกอย่างจะดีเอง แต่ถ้าข้อมูลภายในยังแยกกันคนละระบบ ลูกค้าอยู่ CRM ฝั่งหนึ่ง พฤติกรรมเว็บอยู่อีกฝั่ง ข้อมูล consent ก็ไม่ sync กัน แบบนี้ AI ก็มีโอกาสตอบผิดสูงอยู่ดี
เปรียบง่ายๆ เหมือนเราเอาพนักงานเก่งมากเข้ามาทำงาน แต่ส่งข้อมูลผิด ส่งข้อมูลเก่า หรือให้ข้อมูลไม่ครบ ต่อให้เก่งแค่ไหนก็ตัดสินใจพลาดได้
จุดที่ผมเห็นด้วยมากคือคำว่า “AI problem is actually an orchestration problem”
เพราะโลกตอนนี้ไม่ได้ขาดโมเดลเก่งๆ แล้ว แต่กำลังขาด “ระบบจัดการข้อมูล” ที่ทำให้ AI เข้าถึง context ที่ถูกต้อง แบบ real-time และมี governance จริงๆ
ยิ่งยุค Agentic AI กำลังมา เรื่องนี้ยิ่งสำคัญ
อนาคต AI จะไม่ได้แค่ตอบคำถาม แต่จะ “ลงมือทำงานแทน” เช่น จองตั๋ว ซื้อของ อนุมัติงาน ประสานหลายระบบพร้อมกัน ถ้าข้อมูลมั่ว หรือ permission พัง ความเสียหายจะหนักกว่ายุค chatbot หลายเท่า
ผมว่าหลายองค์กรตอนนี้กำลังโฟกัสผิดจุด คือรีบไล่ตามว่าใช้โมเดลอะไร แต่ยังไม่ได้ลงทุนจริงจังกับ data flow, identity resolution, consent layer หรือ orchestration pipeline
สุดท้ายเลยได้ AI ที่เดโมสวย แต่พอใช้งานจริงกลับงงลูกค้าเอง
ช่วงหลังจะเห็นบทความและงานวิจัยหลายที่เริ่มพูดไปในทางเดียวกันว่า “ปัญหาหลักของ Enterprise AI คือเรื่องระบบข้อมูลและ orchestration” มากกว่าความฉลาดของโมเดลแล้ว
ส่วนตัวคิดว่านี่น่าจะเป็นเหตุผลว่าทำไมบางองค์กรใช้ AI แล้ว productivity พุ่งจริง แต่บางที่กลับรู้สึกว่า “ก็แค่ของเล่นแพงๆ”
สุดท้าย คนที่จะได้เปรียบอาจไม่ใช่คนที่มี AI ฉลาดที่สุด แต่เป็นคนที่ “จัดการข้อมูลและ workflow ได้ดีที่สุด”


AI เก่งขึ้นทุกวัน…แต่ทำไมหลายองค์กรยังใช้แล้ว “ไม่เวิร์ก” ?
พอได้อ่านบทความนี้แล้วรู้สึกว่า “เออ มันตรงมาก”
ข่าวต้นฉบับ: https://aimagazine.com/news/tealium-why-enterprise-ai-is-orchestration-problem
บทความพูดถึงประเด็นที่คนชอบมองข้าม คือปัญหาของ AI ในองค์กรจำนวนมาก จริงๆ ไม่ได้อยู่ที่ตัวโมเดล แต่เป็น “ระบบหลังบ้าน” ที่ส่งข้อมูลให้ AI มากกว่า
หลายองค์กรคิดว่าเปลี่ยนไปใช้โมเดลใหม่ แพงขึ้น ฉลาดขึ้น เดี๋ยวทุกอย่างจะดีเอง แต่ถ้าข้อมูลภายในยังแยกกันคนละระบบ ลูกค้าอยู่ CRM ฝั่งหนึ่ง พฤติกรรมเว็บอยู่อีกฝั่ง ข้อมูล consent ก็ไม่ sync กัน แบบนี้ AI ก็มีโอกาสตอบผิดสูงอยู่ดี
เปรียบง่ายๆ เหมือนเราเอาพนักงานเก่งมากเข้ามาทำงาน แต่ส่งข้อมูลผิด ส่งข้อมูลเก่า หรือให้ข้อมูลไม่ครบ ต่อให้เก่งแค่ไหนก็ตัดสินใจพลาดได้
จุดที่ผมเห็นด้วยมากคือคำว่า “AI problem is actually an orchestration problem”
เพราะโลกตอนนี้ไม่ได้ขาดโมเดลเก่งๆ แล้ว แต่กำลังขาด “ระบบจัดการข้อมูล” ที่ทำให้ AI เข้าถึง context ที่ถูกต้อง แบบ real-time และมี governance จริงๆ
ยิ่งยุค Agentic AI กำลังมา เรื่องนี้ยิ่งสำคัญ
อนาคต AI จะไม่ได้แค่ตอบคำถาม แต่จะ “ลงมือทำงานแทน” เช่น จองตั๋ว ซื้อของ อนุมัติงาน ประสานหลายระบบพร้อมกัน ถ้าข้อมูลมั่ว หรือ permission พัง ความเสียหายจะหนักกว่ายุค chatbot หลายเท่า
ผมว่าหลายองค์กรตอนนี้กำลังโฟกัสผิดจุด คือรีบไล่ตามว่าใช้โมเดลอะไร แต่ยังไม่ได้ลงทุนจริงจังกับ data flow, identity resolution, consent layer หรือ orchestration pipeline
สุดท้ายเลยได้ AI ที่เดโมสวย แต่พอใช้งานจริงกลับงงลูกค้าเอง
ช่วงหลังจะเห็นบทความและงานวิจัยหลายที่เริ่มพูดไปในทางเดียวกันว่า “ปัญหาหลักของ Enterprise AI คือเรื่องระบบข้อมูลและ orchestration” มากกว่าความฉลาดของโมเดลแล้ว
ส่วนตัวคิดว่านี่น่าจะเป็นเหตุผลว่าทำไมบางองค์กรใช้ AI แล้ว productivity พุ่งจริง แต่บางที่กลับรู้สึกว่า “ก็แค่ของเล่นแพงๆ”
สุดท้าย คนที่จะได้เปรียบอาจไม่ใช่คนที่มี AI ฉลาดที่สุด แต่เป็นคนที่ “จัดการข้อมูลและ workflow ได้ดีที่สุด”