==แนะนำวิธีการใช้งานเอไอแปลงข้อความเป็นรูปภาพ (text to image) ของ google gemini และ microsoft copilot สำหรับการศึกษา,งานทั่วไป==
 การใช้ AI วาดรูปฟรี
การใช้ AI วาดรูปฟรี
เทคโนโลยีพัฒนาไปมาก มากจนแปลกใจว่าทำไมไปเร็วแบบนี้ สมมติว่าเราไปบวช ฝึกท่องขานนาค เอสาหังภันเต สุจิระปรินิพพุตัมปิ ฯลฯ เป็นผ้าขาวและบวชสักเดือนนึงกลับมา ระหว่างบวชภาวนาไม่สนทางโลก มุ่งแต่ทางธรรม กลับมาคงตกใจกับความรวดเร็วของการพัฒนาด้านต่างๆ โดยเฉพาะด้านเอไอหรือปัญญาประดิษฐ์ และลองจินตนาการถึงเทคโนโลยีในอีกสิบปีข้างหน้าจะพัฒนาไปแค่ไหนกันก็น่าสนใจ หรือ AGI จะมาเร็วกว่าที่หลายคนคาดคิดกัน
ตอนนี้หลายๆคนอาจคุ้นชินกับการใช้ chatgpt ซึ่งนับเป็น generative ai หมายถึงปัญญาประดิฐษ์ที่สามารถสร้างคอนเทนต์ใหม่ๆต่างๆมาได้ chatgpt เปิดตัวมาในปลายปี 2022 ในตอนเปิดตัวนั้น คอนเทนต์ที่สร้างคือคือข้อความ โดยเรากรอก prompt เป็นข้อความลงไป มันก็จะตอบกลับเรามาเป็นข้อความ
แต่เมื่อคิดดูให้ดี คอนเทนต์แท้จริงแล้วไม่ได้มีข้อความ อาจจะเป็นรูปภาพ วิดีโอ เสียง หรืออื่นๆก็ได้ มันอาจจะเป็นได้หลายแบบ เช่น
text to text
text to image
text to sound
text to video
หรือแม้แต่ตอนอินพุตมาในพร้อมก็อาจจะไม่จำเป็นต้องเป็น text ก็ได้ อาจจะเป็น
image to text
image to image
image to sound
image to video
เป็นต้น
อย่างที่หลายคนอาจจะเคยเห็นข่าวไปแล้ว แค่เรากรอกข้อความ ด้วยความฉลาดของเอไอมันก็จะแปลงเป็นวิดีโอได้อย่างสวยงาม เช่น sora ของ openai

ซึ่งน่าเสียดายที่ ณ ตอนนี้ต้นปี 2024 text to video ยังไม่ให้คนทั่วไปได้ใช้ แต่ก็มีเรื่องที่น่ายินดีคือ text to image สามารถเข้าใช้ได้แล้วหลายแห่ง แถมยังมีตัวที่ใช้ฟรีและดีด้วย ซึ่งในกระทู้นี่จะพูดถึงการใช้งาน text to image อธิบายหลักการพื้นฐาน แนะนำการใช้งานขั้นต้น เน้นทางด้านการศึกษา งานทั่วไปเป็นหลักและเปรียบเทียบการทำงานของ สองตัวนี้คือ
1 google gemini (เดิมคือ bard)
2 microsoft copilot
สองตัวนี้ใช้งานได้ง่าย ฟรี ภาพความละเลียนด hd สวย ใช้งานผ่านบราวเซอร์ได้เลย มันจะต่อคราวด์และสร้างภาพมาให้เราเอง การใช้งานถือว่าไม่ช้ามาก ความจริงแล้ว text to image ยังมีออีกหลายเจ้า เช่น chatgpt plus ซึ่งต้องเสียเงิน , midjourney ใช้งานผ่าน discord และเสียเงิน , stable diffusion อันนี้ไม่ต้องผ่านคราวด์ ลงและใช้คอมเราประมวลผลได้เลย และก็ยังมีอีกหลายเจ้าในอินเตอเนท
ก่อนที่จะอธิบายหลักการทำงานของมันคร่าวๆ หลังจากอ่าน nyt แล้ว ทำให้รู้จักมีอีกเวบนึงที่น่าสนใจ อยากจะมาแนะนำคือ Perplexity.ai ซึ่งกำลังได้รับความนิยมมากขึ้นเรื่อยๆใน ตปท ซึ่งมันเป็นเหมือน search engine ที่ใช้เอไอเข้ามาช่วยด้วย อย่างเช่นในอดีต สมมติว่าเราอยากรู้เรื่องอะไร เราก็จะกูเกิล แล้วกูเกิลมันก็จะแสดงเวบที่เกี่ยวข้องมีเรื่องเหล่านั้นมาให้เราดู แต่สำหรับ Perplexity.ai มันจะค้นข้อมูลในอินเตอเนทแล้วก็สรุปรวบรวมเป็นคำพูดพร้อมทั้งลิงค์อ้างอิง แสดงเป็นข้อความอธิบายให้เราฟัง โดยเราสามารถถามต่อไปเรื่อยๆได้อีกด้วย เหมือนคุยกันคน เลขาผู้เป็นนักปราชญ์ทุกสาขาวิชา (แต่บางทีก็อาจจะมั่วบ้างต่องคอยตรวจสอบให้ดีด้วย)
โดยสามารถเข้าไปใช้งานได้ที่
https://www.perplexity.ai ตัวอย่างเราพิมพ์ลงพร้อมว่า "property of addition." เพราะเราสนใจเรื่องคุณสมบัติของการบวก เพราะเราอ่านตำรา Basic mathematics ของ Lang แต่มันไม่เบสิคดังชื่อตำราเลย เราปวดหัวมาก จึงมาขอความช่วยเหลือจากเอไอ
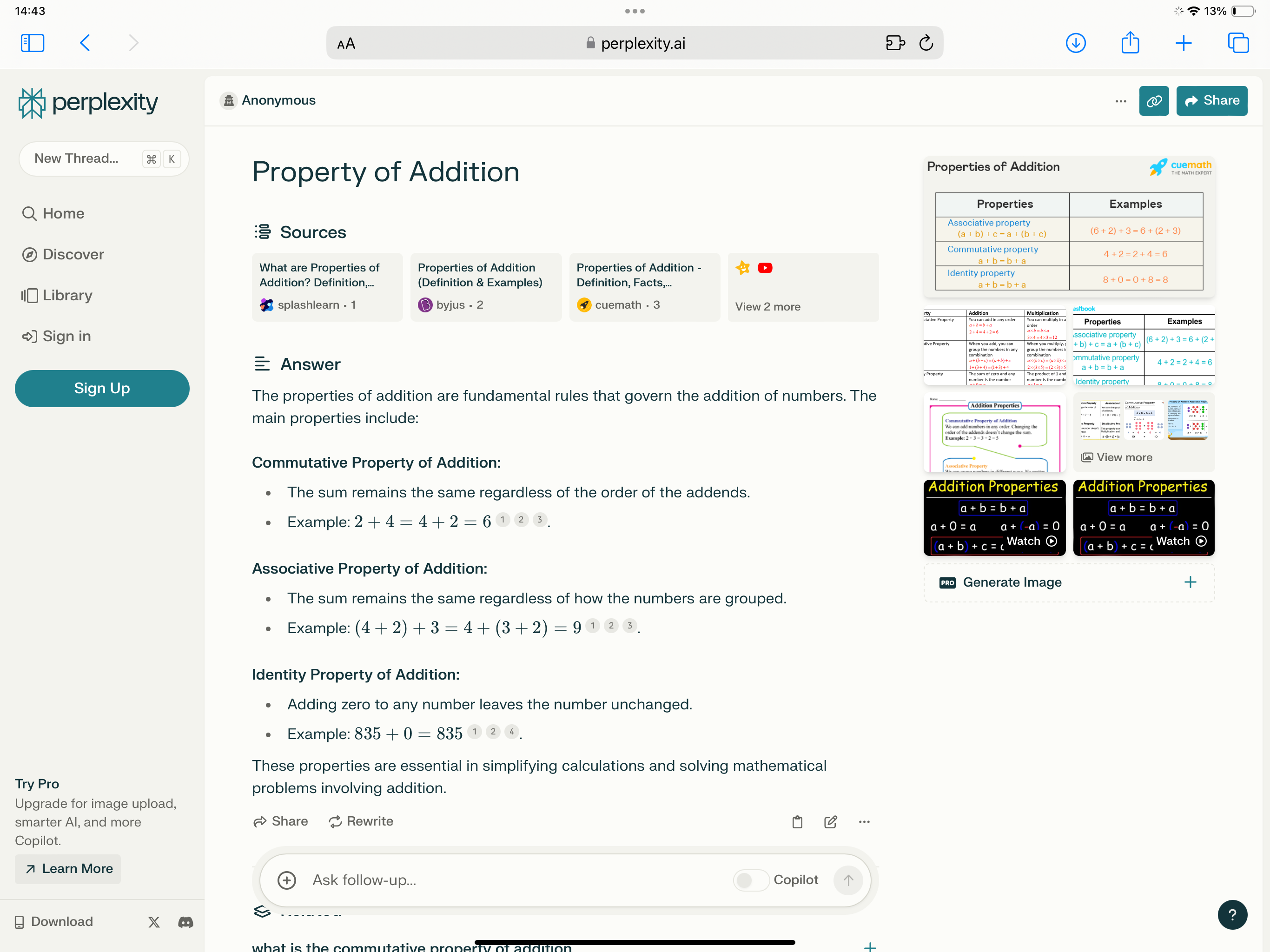
Perplexity.ai ก็จะสรุปมาให้เรา พร้อมยกตัวอย่างมาด้วย เหมาะกับการช่วยสำหรับการเรียนรู้ด้วยตัวเอง บางคำถามเราสงสัย เราพิมพ์ถามเป็นคำถาม กูเกิลอาจตอบไม่ได้ถ้ามันไม่เจอเวบที่มีข้อความคล้าย แต่เวบนี้มันจะพยายามทำความเข้าใจว่าเราถามอะไร มันก็จะพยายามคุยตอบเรา ข้อดีของเวบนี้คือมันต่ออินเตอเนท อาจเป็นอีกหนึ่งทางเลือกสำหรับใช้ควบคู่ไปกับกูเกิล สำหรับการศึกษา ค้นคว้า

ที่ลองใช้ดูทางด้าน ฟิสิกส์และคณิตศาสตร์จะพบว่าเนื้อหาที่ได้ค่อนข้างถูกต้อง แสดงอ้างอิงไว้สามารถไปศึกษาเพิ่มเติมในลิงค์ได้เลย และยังสามารถแสดงผลเป็นสมการทางคณิตศาสตร์ได้อีกด้วย
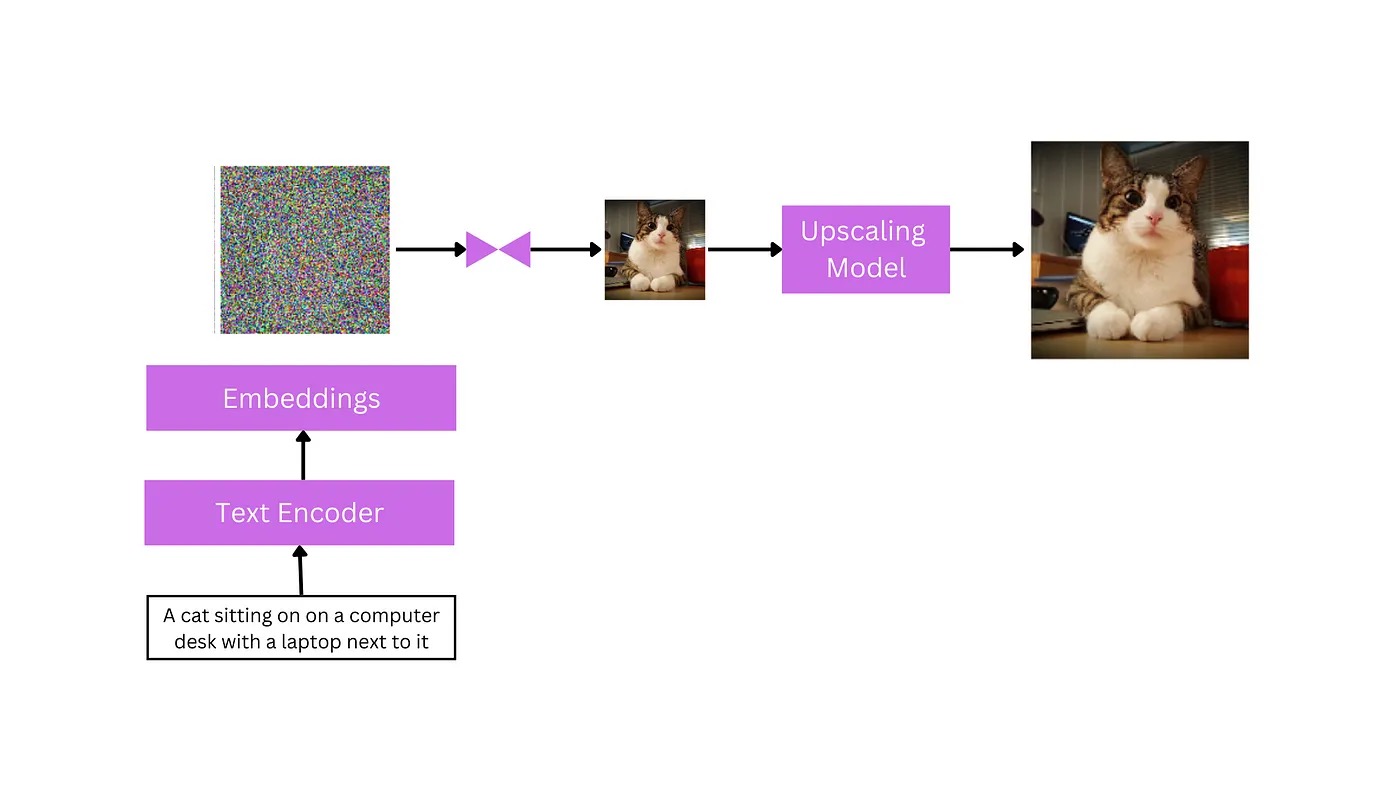
ทีนี้กลับมาที่เรื่อง text to image มันมีหลายวิธีด้วยกัน แต่ที่นิยมกันเราเรียกว่า Diffusion model ซึ่งหลักการของมันเต็มไปด้วยสมการคณิตศาสตร์อันสวยงามเต็มไปหมด แต่เราก็พอจะอธิบายโดยไม่ใช้สมการได้คือ สมมติเรามีภาพน้องแมวเหมียวอยู่ เราค่อยๆเพิ่ม noise เข้าไปในภาพเป็นสเตป มากขึ้นเรื่อยๆ noise ก็เหมือนตอนเราถ่ายภาพกล้อง dslr คือจะเป็นจุดๆๆสีในภาพทำให้ภาพเราไม่ค่อยชัด เมื่อเพิ่มไปเรื่อยๆ พอมากเข้า ในภาพก็มีแต่ noise เต็มไปหมดจนเราไม่เห็นแมวเหมียว ซึ่งวิธีนี้เราเรียกว่า Forward Diffusion Process แต่ในทางกลับกันถ้าในภาพเราเต็มไป noise เต็มไปหมด แต่เราจะลด noise ลงไปเรื่อยๆ เป็นสเตปไปเรื่อยๆ สุดท้ายได้ภาพน้องแมว วิธีการขั้นตอนที่ย้อนกลับนี้เราเรียกว่า Reverse Diffusion Process หรืออาจเรียกว่ากระบวนการ denoising ซึ่งเราต้องฝึกโมเดลให้มันทั้งสองกระบวนการนี้ให้มันบ่อยๆ ให้ข้อมูลที่ใช้เทรนมันเยอะๆ ใช้รูปเยอะๆ มันจะได้สามารถแปลงจาก noise เป็นรูปต่างๆได้เก่งขึ้นโดย ต้องนำ ข้อความมาเทรนมันว่า ข้อความนี้เกี่ยวกับรูปแนวๆนี้ อีกข้อความหนึ่งสัมพันธ์กับรูปอีกแนวนี้ๆ โดยการช่วยสร้างจาก noise กลายเป็นรูปต่างๆโดยมี ข้อความช่วยบอกให้ ซึ่งเอไอจะเข้าใจข้อความใน พร้อมที่เรากรอกให้โดยผ่าน text encoder

และสมมติเมื่อได้ภาพมาแล้วก็มาอัพสเกลจากภาพแมวเหมียวที่ได้รูปเล็กๆ มาอัพสเกล ก็จะได้รูปคมชัดขึ้น เรื่อง upscale นี้คนที่ชอบดูหนังหรือเล่นเกม เป็น pc master race ก็จะผ่านตามาบ้าง ตอนตั้งค่าภาพตอนเล่นเกม เพราะมันจะทำให้ภาพที่เราดูหนังหรือเล่นเกมคมชัดมากยิ่งขึ้น โดยเช่น วิธีการ supersampling พวก DLSS เป็นต้น มันยังช่วยลดโหลดของ gpu อีกด้วย
ต่อมาก็จะแนะนำวิธีการใช้งานแปลงข้อความเป็นรูปภาพ (text to image) นะครับ
เดี๋ยวมาเขียนต่อครับ ถ้าชอบช่วยกดบวก กดถูกใจด้วยนะครับ ขอบคุณครับ
- จขกท. สุดหล่อ

==แนะนำการใช้เอไอแปลงข้อความเป็นรูปภาพ(text to image) ของ google gemini และ microsoft copilot สำหรับการศึกษา,งานทั่วไป==
การใช้ AI วาดรูปฟรี
เทคโนโลยีพัฒนาไปมาก มากจนแปลกใจว่าทำไมไปเร็วแบบนี้ สมมติว่าเราไปบวช ฝึกท่องขานนาค เอสาหังภันเต สุจิระปรินิพพุตัมปิ ฯลฯ เป็นผ้าขาวและบวชสักเดือนนึงกลับมา ระหว่างบวชภาวนาไม่สนทางโลก มุ่งแต่ทางธรรม กลับมาคงตกใจกับความรวดเร็วของการพัฒนาด้านต่างๆ โดยเฉพาะด้านเอไอหรือปัญญาประดิษฐ์ และลองจินตนาการถึงเทคโนโลยีในอีกสิบปีข้างหน้าจะพัฒนาไปแค่ไหนกันก็น่าสนใจ หรือ AGI จะมาเร็วกว่าที่หลายคนคาดคิดกัน
ตอนนี้หลายๆคนอาจคุ้นชินกับการใช้ chatgpt ซึ่งนับเป็น generative ai หมายถึงปัญญาประดิฐษ์ที่สามารถสร้างคอนเทนต์ใหม่ๆต่างๆมาได้ chatgpt เปิดตัวมาในปลายปี 2022 ในตอนเปิดตัวนั้น คอนเทนต์ที่สร้างคือคือข้อความ โดยเรากรอก prompt เป็นข้อความลงไป มันก็จะตอบกลับเรามาเป็นข้อความ
แต่เมื่อคิดดูให้ดี คอนเทนต์แท้จริงแล้วไม่ได้มีข้อความ อาจจะเป็นรูปภาพ วิดีโอ เสียง หรืออื่นๆก็ได้ มันอาจจะเป็นได้หลายแบบ เช่น
text to text
text to image
text to sound
text to video
หรือแม้แต่ตอนอินพุตมาในพร้อมก็อาจจะไม่จำเป็นต้องเป็น text ก็ได้ อาจจะเป็น
image to text
image to image
image to sound
image to video
เป็นต้น
อย่างที่หลายคนอาจจะเคยเห็นข่าวไปแล้ว แค่เรากรอกข้อความ ด้วยความฉลาดของเอไอมันก็จะแปลงเป็นวิดีโอได้อย่างสวยงาม เช่น sora ของ openai
ซึ่งน่าเสียดายที่ ณ ตอนนี้ต้นปี 2024 text to video ยังไม่ให้คนทั่วไปได้ใช้ แต่ก็มีเรื่องที่น่ายินดีคือ text to image สามารถเข้าใช้ได้แล้วหลายแห่ง แถมยังมีตัวที่ใช้ฟรีและดีด้วย ซึ่งในกระทู้นี่จะพูดถึงการใช้งาน text to image อธิบายหลักการพื้นฐาน แนะนำการใช้งานขั้นต้น เน้นทางด้านการศึกษา งานทั่วไปเป็นหลักและเปรียบเทียบการทำงานของ สองตัวนี้คือ
1 google gemini (เดิมคือ bard)
2 microsoft copilot
สองตัวนี้ใช้งานได้ง่าย ฟรี ภาพความละเลียนด hd สวย ใช้งานผ่านบราวเซอร์ได้เลย มันจะต่อคราวด์และสร้างภาพมาให้เราเอง การใช้งานถือว่าไม่ช้ามาก ความจริงแล้ว text to image ยังมีออีกหลายเจ้า เช่น chatgpt plus ซึ่งต้องเสียเงิน , midjourney ใช้งานผ่าน discord และเสียเงิน , stable diffusion อันนี้ไม่ต้องผ่านคราวด์ ลงและใช้คอมเราประมวลผลได้เลย และก็ยังมีอีกหลายเจ้าในอินเตอเนท
ก่อนที่จะอธิบายหลักการทำงานของมันคร่าวๆ หลังจากอ่าน nyt แล้ว ทำให้รู้จักมีอีกเวบนึงที่น่าสนใจ อยากจะมาแนะนำคือ Perplexity.ai ซึ่งกำลังได้รับความนิยมมากขึ้นเรื่อยๆใน ตปท ซึ่งมันเป็นเหมือน search engine ที่ใช้เอไอเข้ามาช่วยด้วย อย่างเช่นในอดีต สมมติว่าเราอยากรู้เรื่องอะไร เราก็จะกูเกิล แล้วกูเกิลมันก็จะแสดงเวบที่เกี่ยวข้องมีเรื่องเหล่านั้นมาให้เราดู แต่สำหรับ Perplexity.ai มันจะค้นข้อมูลในอินเตอเนทแล้วก็สรุปรวบรวมเป็นคำพูดพร้อมทั้งลิงค์อ้างอิง แสดงเป็นข้อความอธิบายให้เราฟัง โดยเราสามารถถามต่อไปเรื่อยๆได้อีกด้วย เหมือนคุยกันคน เลขาผู้เป็นนักปราชญ์ทุกสาขาวิชา (แต่บางทีก็อาจจะมั่วบ้างต่องคอยตรวจสอบให้ดีด้วย)
โดยสามารถเข้าไปใช้งานได้ที่ https://www.perplexity.ai ตัวอย่างเราพิมพ์ลงพร้อมว่า "property of addition." เพราะเราสนใจเรื่องคุณสมบัติของการบวก เพราะเราอ่านตำรา Basic mathematics ของ Lang แต่มันไม่เบสิคดังชื่อตำราเลย เราปวดหัวมาก จึงมาขอความช่วยเหลือจากเอไอ
Perplexity.ai ก็จะสรุปมาให้เรา พร้อมยกตัวอย่างมาด้วย เหมาะกับการช่วยสำหรับการเรียนรู้ด้วยตัวเอง บางคำถามเราสงสัย เราพิมพ์ถามเป็นคำถาม กูเกิลอาจตอบไม่ได้ถ้ามันไม่เจอเวบที่มีข้อความคล้าย แต่เวบนี้มันจะพยายามทำความเข้าใจว่าเราถามอะไร มันก็จะพยายามคุยตอบเรา ข้อดีของเวบนี้คือมันต่ออินเตอเนท อาจเป็นอีกหนึ่งทางเลือกสำหรับใช้ควบคู่ไปกับกูเกิล สำหรับการศึกษา ค้นคว้า
ที่ลองใช้ดูทางด้าน ฟิสิกส์และคณิตศาสตร์จะพบว่าเนื้อหาที่ได้ค่อนข้างถูกต้อง แสดงอ้างอิงไว้สามารถไปศึกษาเพิ่มเติมในลิงค์ได้เลย และยังสามารถแสดงผลเป็นสมการทางคณิตศาสตร์ได้อีกด้วย
ทีนี้กลับมาที่เรื่อง text to image มันมีหลายวิธีด้วยกัน แต่ที่นิยมกันเราเรียกว่า Diffusion model ซึ่งหลักการของมันเต็มไปด้วยสมการคณิตศาสตร์อันสวยงามเต็มไปหมด แต่เราก็พอจะอธิบายโดยไม่ใช้สมการได้คือ สมมติเรามีภาพน้องแมวเหมียวอยู่ เราค่อยๆเพิ่ม noise เข้าไปในภาพเป็นสเตป มากขึ้นเรื่อยๆ noise ก็เหมือนตอนเราถ่ายภาพกล้อง dslr คือจะเป็นจุดๆๆสีในภาพทำให้ภาพเราไม่ค่อยชัด เมื่อเพิ่มไปเรื่อยๆ พอมากเข้า ในภาพก็มีแต่ noise เต็มไปหมดจนเราไม่เห็นแมวเหมียว ซึ่งวิธีนี้เราเรียกว่า Forward Diffusion Process แต่ในทางกลับกันถ้าในภาพเราเต็มไป noise เต็มไปหมด แต่เราจะลด noise ลงไปเรื่อยๆ เป็นสเตปไปเรื่อยๆ สุดท้ายได้ภาพน้องแมว วิธีการขั้นตอนที่ย้อนกลับนี้เราเรียกว่า Reverse Diffusion Process หรืออาจเรียกว่ากระบวนการ denoising ซึ่งเราต้องฝึกโมเดลให้มันทั้งสองกระบวนการนี้ให้มันบ่อยๆ ให้ข้อมูลที่ใช้เทรนมันเยอะๆ ใช้รูปเยอะๆ มันจะได้สามารถแปลงจาก noise เป็นรูปต่างๆได้เก่งขึ้นโดย ต้องนำ ข้อความมาเทรนมันว่า ข้อความนี้เกี่ยวกับรูปแนวๆนี้ อีกข้อความหนึ่งสัมพันธ์กับรูปอีกแนวนี้ๆ โดยการช่วยสร้างจาก noise กลายเป็นรูปต่างๆโดยมี ข้อความช่วยบอกให้ ซึ่งเอไอจะเข้าใจข้อความใน พร้อมที่เรากรอกให้โดยผ่าน text encoder
และสมมติเมื่อได้ภาพมาแล้วก็มาอัพสเกลจากภาพแมวเหมียวที่ได้รูปเล็กๆ มาอัพสเกล ก็จะได้รูปคมชัดขึ้น เรื่อง upscale นี้คนที่ชอบดูหนังหรือเล่นเกม เป็น pc master race ก็จะผ่านตามาบ้าง ตอนตั้งค่าภาพตอนเล่นเกม เพราะมันจะทำให้ภาพที่เราดูหนังหรือเล่นเกมคมชัดมากยิ่งขึ้น โดยเช่น วิธีการ supersampling พวก DLSS เป็นต้น มันยังช่วยลดโหลดของ gpu อีกด้วย
ต่อมาก็จะแนะนำวิธีการใช้งานแปลงข้อความเป็นรูปภาพ (text to image) นะครับ
เดี๋ยวมาเขียนต่อครับ ถ้าชอบช่วยกดบวก กดถูกใจด้วยนะครับ ขอบคุณครับ
- จขกท. สุดหล่อ